How COVID-19 is changing Data Science Workflows
- Dean Pleban
- 6 min read
- 6 years ago
Co-Founder & CEO of DAGsHub. Building the home for data science collaboration. Interested in machine learning, physics and philosophy. Join https://DAGsHub.com | DagsHub Co-Founder & CEO

COVID-19 is changing a lot of things. What can data scientists do to make the most out of the situation?

I’m one of the founders of DAGsHub a platform for data science collaboration, meant for teams not sitting next to each other. I’m not going to discuss the general aspects of COVID-19 and working from home. Instead, I’ll focus specifically on what data scientists need to do work effectively when remote.
When the crisis started, our hypothesis was that existing users’ usage would spike due to the new situation. This is what happened:
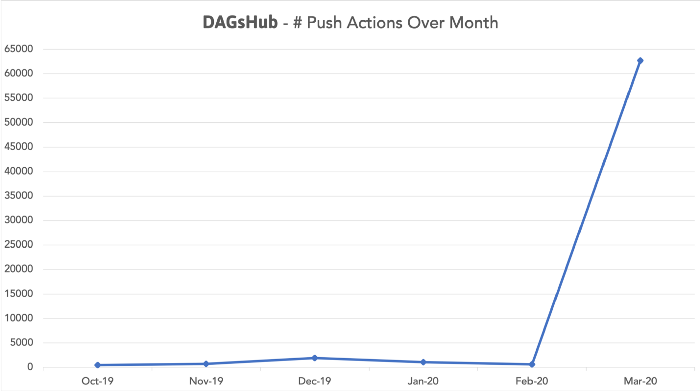
So what the heck is going on here? We thought we had good word of mouth growth and traction with our beta, but the growth since the Coronavirus dwarfs it until it looks like it’s zeroed out.
Our users need tools for project management & collaboration on a much higher frequency than they did when they were sitting next to each other. This proves we need to change our tooling when we transition to remote work.
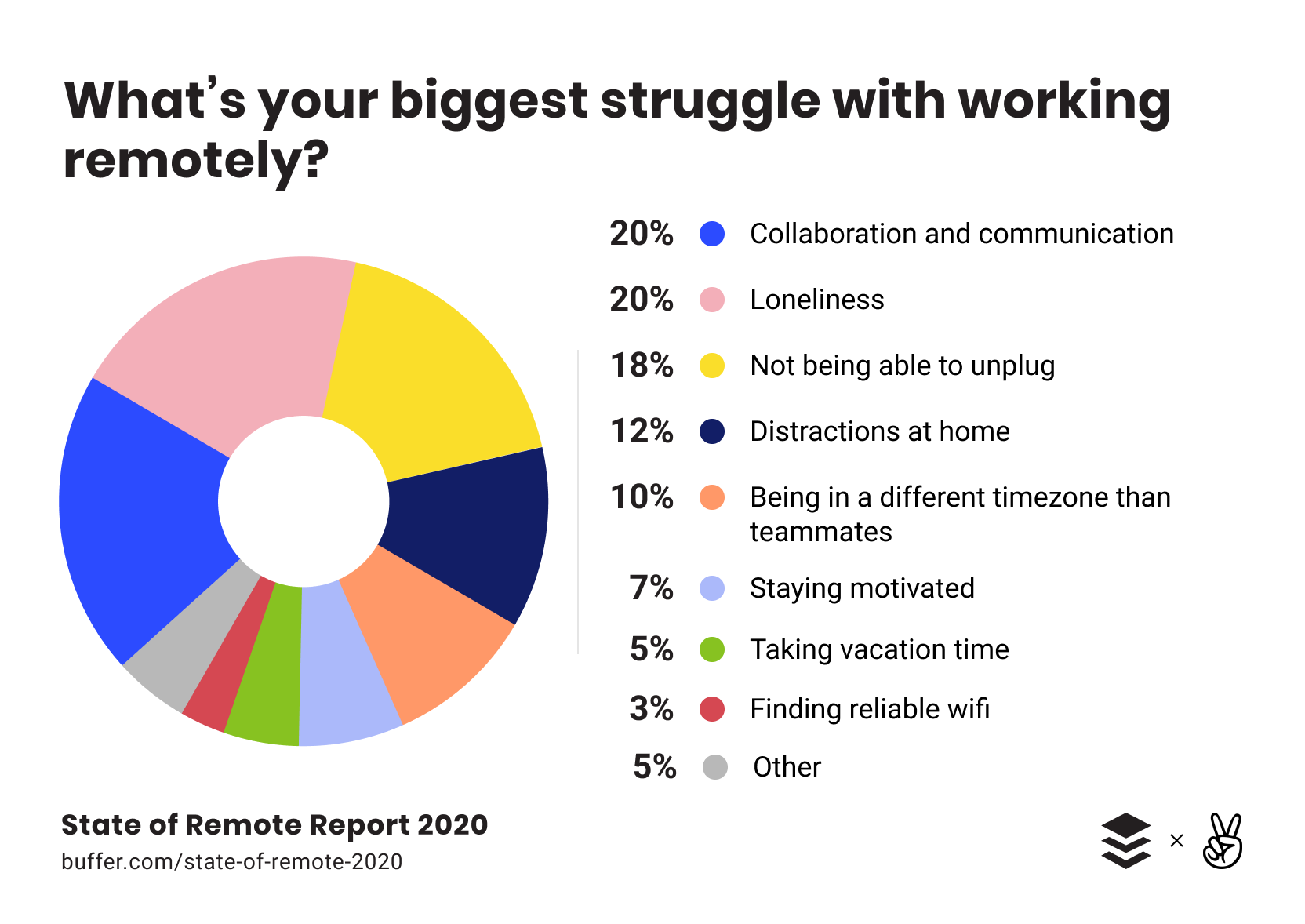
This uptick in usage might also show that bad practices are now hurting teams more than they did in normal times, causing them to rely more on tools that remediate these issues.
Now, you might say — “But this is only push actions, maybe the users are only adding experiments to the platform to look at the metrics and compare between them. Collaboration is a two way street.” You would be right. We would expect a significant rise in pull actions as well, even though this rise would be more subtle as you more often create a new experiment than reproduce one that is already done.
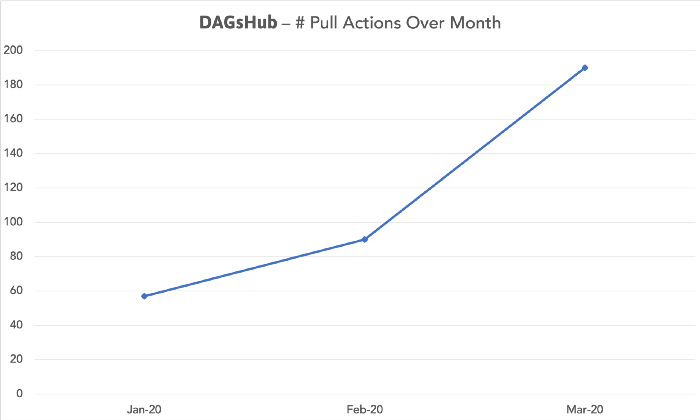
In the last three months, we can see that the number of pull actions has almost tripled.
Let’s dive into the top 4 issues that, in my opinion, stand between us and healthy data science collaboration — especially remotely. These issues are:
- Lack of reproducibility of our experiments
- Bad tracking and logging of our work
- Difficulty in sharing work between collaborators
- Siloed workflows that promote lone wolf mentality and hurt the organization’s productivity in the long run
All of the points above are connected to each other.
Reproducible Experiments
A lot has been written on this topic, Justin Boylan-Toomey’s, take on reproducible data science projects orMatthew Stewart, PhD Researcher’s The Machine Learning Crisis. Debugging your own code might sometimes be difficult, but debugging someone else’s code, when they’re not conveniently available, and when some of the problems might be caused by a difference in the environments you use, is A NIGHTMARE. We need to manage the versions of our code, data, models, and environment in an integrated way so that reproducibility is as easy as humanly possible. This will save a lot of time and grief for yourself and your team members.
Tracking & Logging your Work
This is related and possibly required for reproducibility to be achieved, but it means a lot more than just that. Logging parameters and metrics can be done fairly easily, with auto-logging capabilities created for most of the widely used data science libraries. Doing this properly will let you or your collaborators focus on the important experiments, and easily find the next great thing to try. Usually, an experiment visualization system will be used on top of the experiment data that you log. But to do that, you first have to log your work.

Sharing Work
When people are sitting next to each other, and you’re discussing your work with a colleague, it’s very easy to point at the relevant part in your screen and say “look here, this is what is interesting”. Remote work makes this simple task much more difficult, and teams may find themselves using several different tools with manual syncing between them or, god forbid, emailing links to parts of the project which were uploaded to Google Drive.
The best way to approach the solution for sharing work is built in to the first two issues. If we make sure we have reproducible experiments, and log our work properly, all we need to do in addition is to make sure all of these artifacts are uploaded to a central system. If that is the case, the last step in every experiment would be to git push the results to the platform. Doing this gives you a central web UI where everyone can talk about the same things, creating a common language, and sharing becomes as easy as telling a collaborator to git pull to their system.
Siloed Workflows
The last issue is probably the most difficult, and one which permeates data science work even when we are sitting next to each other — The lone wolf mentality. This issue is not so much a technological one, as it is psychological. We focus on our own work at the expense of the team’s productivity and ability to solve the truly hard problems. In many cases, the former issues mentioned contribute to a vicious cycle, where the tools prevent collaboration, which in turn promotes lone wolf mentality which leads to not developing a collaborative workflow.

Teams that don’t have the tools to support a collaborative workflow are going to feel the downsides of the lone wolf mentality much more strongly with the move to remote work.
The good news is that if you solve the first three issues, you’ve made significant headway towards solving the last one. You can assign more than one person per problem, or assign groups that need to review each other’s work or consult when a problem arises.
That being said, the tools mentioned above are necessary, though not always sufficient. Teamwork is hard and some problems require a tough organizational culture change, like focusing more on process and communication. Setting up the systems required to support a collaborative workflow makes it easier to solve these hard problems.
Solving remote data science with DAGsHub
You can use open source tools for reproducibility or create your own standard (even though the latter isn’t recommended), as well as tools for experiment tracking. But you don’t have to. DAGsHub uses Git and DVC for version control, combining a visual UI for managing your data versions with experiment tracking.
As you’re creating reproducible experiments, you can compare metrics, search for hyper parameters and more. You don’t have to use DVC to use DAGsHub experiment tracking, they complement each other and are completely modular. We are use open source tools and open formats, so you never have to worry about black box solutions and vendor lock in.
DAGsHub is completely free everyone to foster scientific collaboration and battle the Coronavirus crisis. We hope we can help teams ease the transition to remote work, and learn more about what it takes to work successfully in a remote data science environment.
Final words on COVID-19 Projects
Our first and foremost goal at DAGsHub is to support the Open Source Data Science community. If you’re working on a COVID-19 data science project, we’d love to help out with cloud infrastructure, or any other way we can. We have limited capacity, but please reach out to us at covid@dagshub.com if this is relevant to you!
Thanks to Guy Smoilov, Amir Shevat and Siim Teller for their help in writing this piece.



