LLMOps: Experiment Tracking with Weights & Biases for Large Language Models
- Aiswarya Ramachandran
- 3 min read
- 3 years ago


DagsHub simplifies the process of building better models and managing unstructured data projects by consolidating data, code, experiments, and models in one place.
Table of Contents
In the previous article, we explored MLflow's support for experiment tracking of LLM applications through logging of prompts and their outputs.
Another widely used tool for tracking experiments is Weights & Biases (W&B or WandB). This article explores its support for monitoring LLM performance.
To demonstrate its usage, we will use DPT, an LLM-based support chatbot developed by DagsHub. We will check how Weights & Biases log prompts, document the model architecture, and effectively record versioned artifacts.
Weights & Biases Support for Experiment Tracking of LLM
Weights & Biases (W&B) is a platform designed to help machine learning practitioners track, visualize, and optimize their machine learning experiments. It offers a comprehensive suite of features that assist in managing and improving the training process and model performance.
W&B Prompts allows us analyze the inputs and outputs of LLMs, view the intermediate results and securely store and manage our prompts and LLM chain configurations by using tool called “Trace”.
How to use Weights & Biases for Experiment Tracking of LLM
The code for this can be found here
Install Weights & Biases
pip install wandb
Setup and log information
import wandb
from wandb.integration.openai import autolog****
WANDB_NOTEBOOK_NAME ="WANDB-DPT-LOGGING"
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"
wandb.login() # login into wandb using API key
autolog({"project":"dptllm", "job_type": "generation"})
...
wandb.finish()
The Results of Logging LLM Experiments with Weights & Biases
The logs of the experiments are shown in W&B Trace Table, including the input and output passed to the LLM. It also contains information about the LLM Chain and logs any error that occurs as well.
We can see in the Input - the request message - which contains the system message as well as the user message. W&B allows us to download this as csv as well.
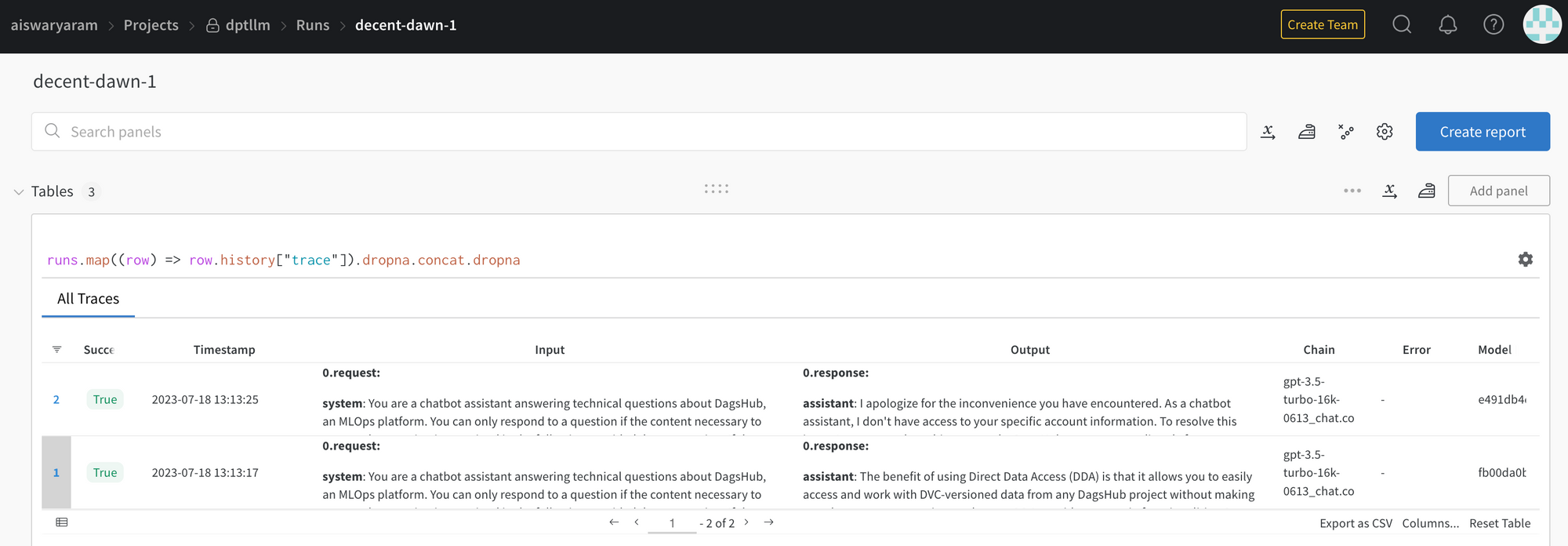
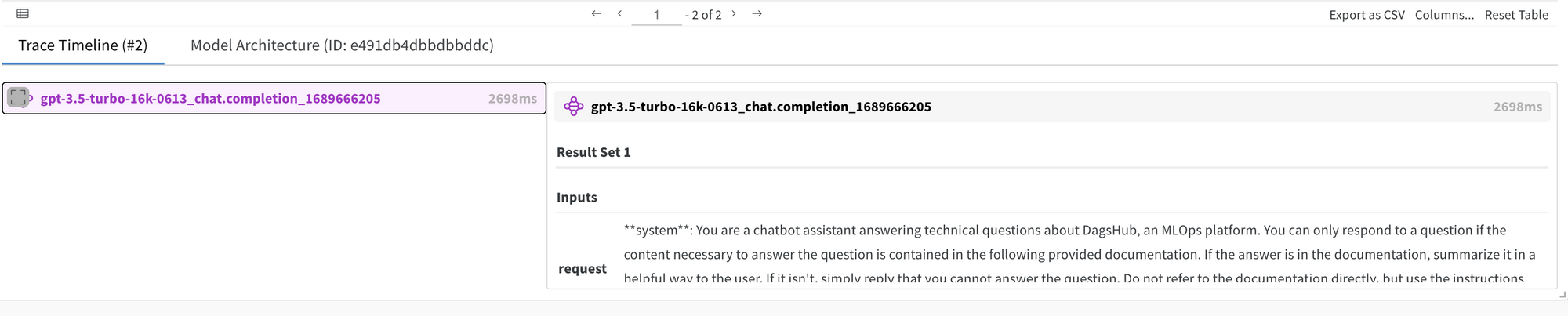
Trace Timeline displays the execution flow of the chain and is color-coded according to component types
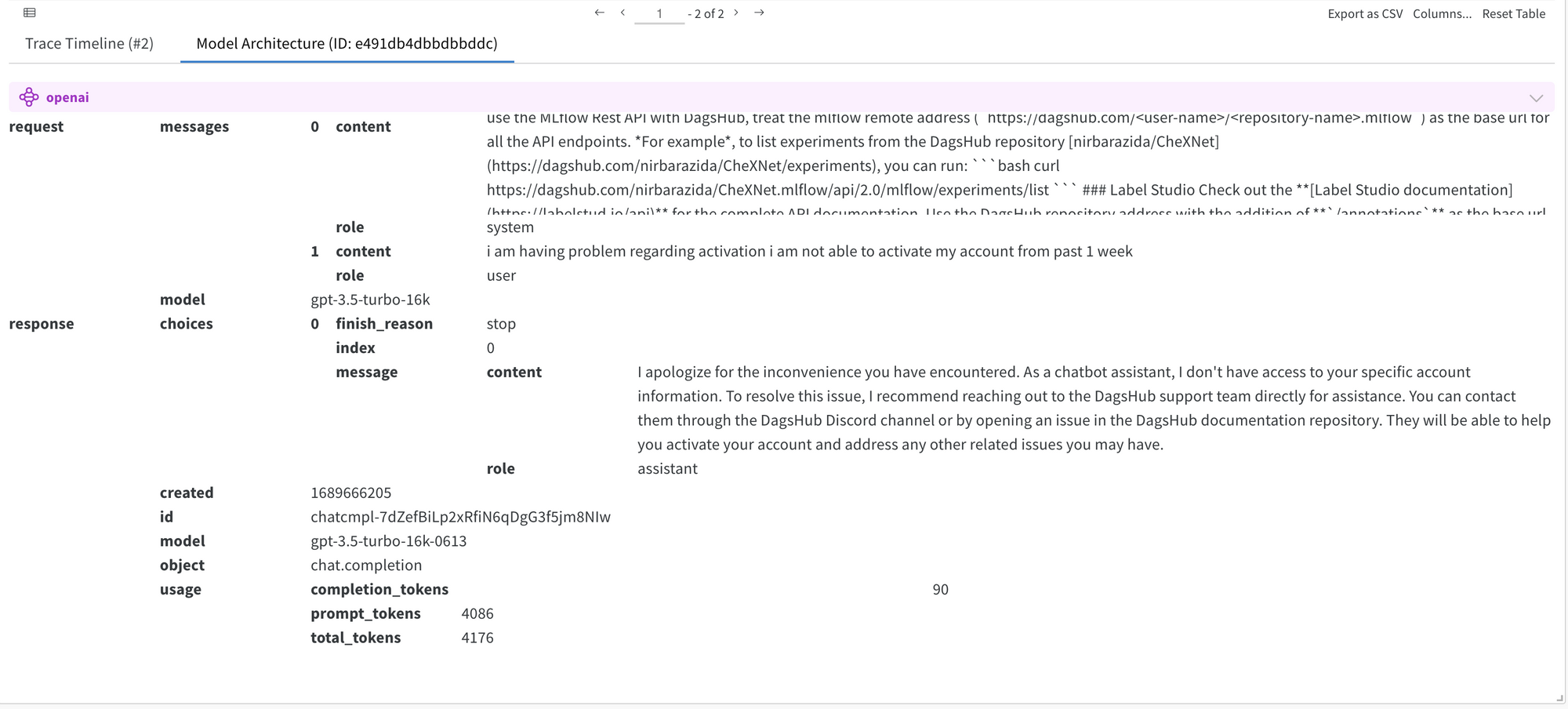
The model architecture tab contains information about the model chain, the number of prompt tokens. It provides details about the structure of the chain and the parameters used to initialize each component of the chain.
W&B Prompts also allows us to save results as artifacts. One can even save an artifact as a dataset. Here is an example of how to do it:
queries=["What is the benefit of using DDA?",
"i am having problem regarding activation i am not able to activate my account from past 1 week"]
final_output=[]
for query in queries:
inputs=generate_input(query,PROMPT,5)
output=chat_completion_dagshub(inputs)
final_output.append({'query':query,'output':output[1],"context":output[2]})
df=pd.DataFrame(final_output)
# log df as a table to W&B for interactive exploration
wandb.log({"queries_examples": wandb.Table(dataframe=df)})
df.to_csv("queries_examples.csv")
# log csv file as an dataset artifact to W&B for later use
artifact = wandb.Artifact("queries_examples", type="dataset")
artifact.add_file("queries_examples.csv")
wandb.log_artifact(artifact)
....
wandb.finish()
Across multiple runs, the versions of the artifact are also maintained.
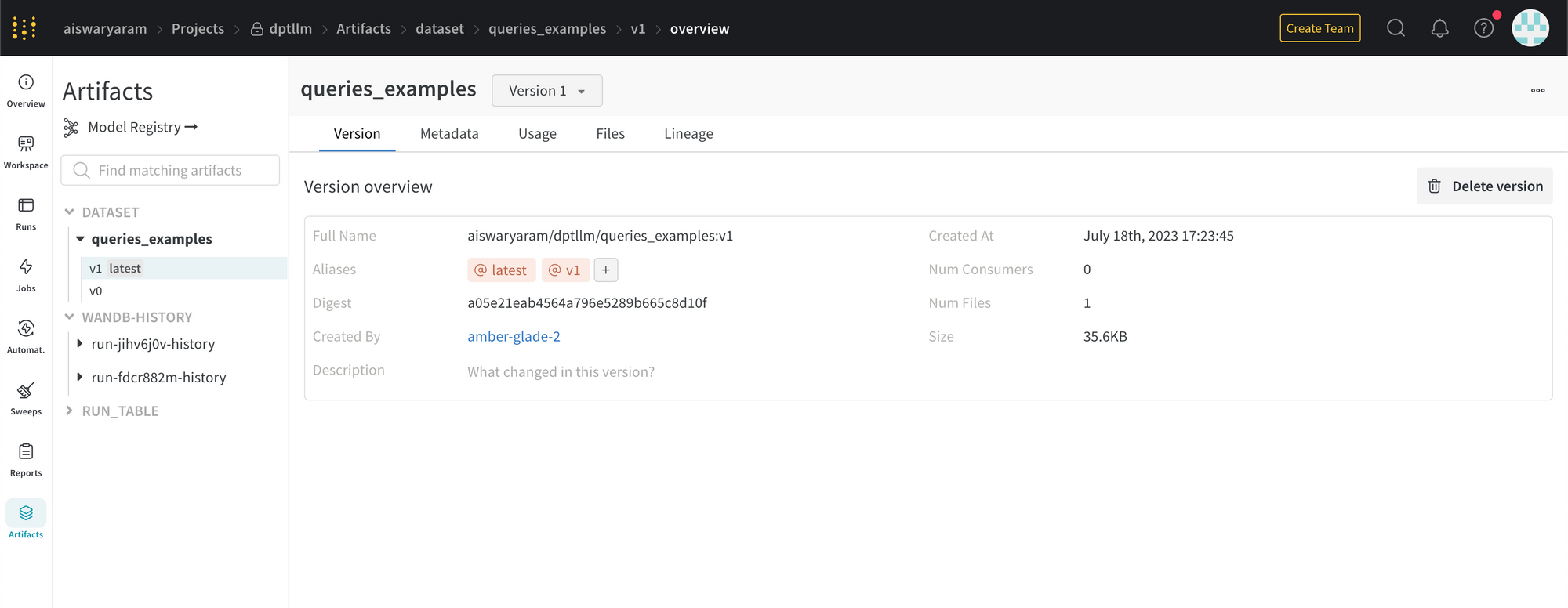
While W&B allows to save artifacts as different versions, we are not able to compare the results of various versions side by side.
Conclusion
W&B Prompts stands out for its parameter logging simplicity compared to MLflow, as it does not require explicit logging of parameters. Additionally, W&B Prompts offers an intuitive UI that enables easy exploration of results and the creation of Reports from runs, providing an excellent platform for experiment tracking.
If you used W&B for tracking experiments for LLMs we'd love to hear your thoughts! Share them with us and our community on Discord



